
前言
YOLO(You Only Look Once)是一种基于深度学习的目标检测算法,用于在图像或视频中识别和定位物体。它是一种实时目标检测算法,以其速度快、精度高而著称。🔗YOLO的官网。官方提供的YOLO11模型已经经过了coco(貌似是coco8)数据集的训练,能够识别80种日常生活中的物体,🔗coco数据集。
下面是一个PYTHON例子,能实时(将调用电脑自带的摄像头)检测并框选画面中的人脸:
1 | import cv2 |
可以看见,其中不包括我需要检测的目标,无人机(drone),也就是说此时的YOLO模型是不认识“无人机”这个物体的。所以接下来需要用无人机的数据集对YOLO进行训练,使其能识别无人机。
准备工作
环境
完整的训练、运行YOLO模型需要的环境如下(无虚拟环境,可能具有时效性,请以官网为准):🔗官方提供的训练文档
| 类别 | 推荐版本/工具 | 备注 |
|---|---|---|
| 操作系统 | Windows 10 / 11 | 支持 GPU 加速的 64 位系统 |
| GPU 驱动 | NVIDIA Game Ready Driver / Studio Driver | 确保 CUDA 兼容 |
| CUDA | CUDA 12.0 或以上 | GPU 加速所需 |
| cuDNN | cuDNN 8.x | 深度学习库,配合 CUDA 使用 |
| Python | Python 3.8 - 3.11 | 推荐使用 Anaconda 管理环境 |
| PyTorch | PyTorch 2.1 或以上 | 支持 GPU 训练,需匹配 CUDA 版本 |
| TorchVision | 适配版本(与 PyTorch 版本匹配) | 处理图像数据的 PyTorch 模块 |
| YOLO 版本 | YOLOv5 / YOLOv8 / YOLOv11 | 使用 Ultralytics YOLO 系列或最新版本 |
| OpenCV | OpenCV 4.7 或以上 | 图像处理及显示 |
| Numpy | 最新版本 | 科学计算库 |
| Matplotlib | 最新版本 | 可视化检测结果 |
| tqdm | 最新版本 | 显示训练进度条 |
| pycocotools | 最新版本 | 用于解析 COCO 数据集 |
| Git | 最新版本 | 克隆 YOLO 仓库 |
| Visual Studio | 2022 或以上 | CUDA 和 cuDNN 编译依赖 |
| 数据集 | COCO / 自定义数据集 | 根据需求选择 |
| 模型权重 | yolov11n.pt / yolov11s.pt 等 | 根据需求选择轻量级或精确模型 |
其中很多环境是附属关系,也就是说我们安装了其中一个,另外的也能随之安装好,下面是几个安装的实例:
安装CUDA
🔗下载DUDA TOOKIT一般情况下,安装完CUDA,cudnn也会自动安装。
检验安装:
1 | nvcc --version |
安装带GPU支持的PYTORCH
1 | pip uninstall torch torchvision torchaudio |
cu118表示CUDA 11.8,如果你使用的是CUDA 12,请换成cu121。
检验PyTorch 是否检测到 GPU:
1 | python -c "import torch; print(torch.cuda.is_available())" |
检验兼容性:
1 | python -c "import torch; print(torch.version.cuda)" |
安装模型及算法
1 | pip install ultralytics |
安装其他环境(有些可能已经安装好了)
1 | pip install numpy |
数据集准备
一个好的数据集直接决定了模型的训练效果,数据集的质量是非常重要的。当然,自己制作数据集也行,但是非常耗时间和精力,这里我用的是robowflow上面的免费公开数据集,里面包含了9000多张各种环境下无人机的图片,以及标注数据。👉robowflow官网的数据集,选择YOLO11格式下载。下载解压完之后,目录结构应该是这样的:
在其他条件相同的情况下。数据集越大(即包含越多的样本),训练的结果就会越精确,但是训练时间也会越长。
选择模型权重
YOLO11模型有很多版本,有轻量版,有精确版,有大模型,有小模型,取决于硬件条件。
| 模型版本 | 模型大小(MB) | 参数量(M) | 推理速度(ms) | 推荐场景 |
|---|---|---|---|---|
| YOLO11n | 5-6 MB | 4-5 M | 1-2 ms | 轻量化设备、实时检测 |
| YOLO11s | 10-15 MB | 8-10 M | 3-4 ms | 移动端设备、实时检测 |
| YOLO11m | 30-40 MB | 25-30 M | 5-7 ms | 中等算力设备、无人机检测 |
| YOLO11l | 80-100 MB | 50-60 M | 8-10 ms | 高精度场景、大型检测任务 |
| YOLO11x | 150-200 MB | 90-100 M | 10-15 ms | 超高精度任务、工业检测 |
由于将来可能将程序植入到单片机上,我使用的是YOLO11n模型,这个模型的参数量最小,速度最快,对硬件算力要求很低。
开始训练
首先进入数据集文件夹,修改data.yaml文件,将里面的train,val,test路径修改为实际路径,例如,我的就是:
1 | train: D:\YOLO\UAVs.v2i.yolov11\train\images |
随后在该文件夹下右键,打开powershell,输入以下命令以启动训练:
1 | yolo train model=yolo11n.pt data=data.yaml epochs=50 batch=16 imgsz=640 |
其中:
model=yolo11n.pt:加载预训练模型
data=data.yaml:指定数据集配置
epochs=50:训练50个epoch(一般来说150-200是最佳选择,但我为了快速训练,将其降低到50)
batch=16:批量大小根据显存选择
imgsz=640:图像输入尺寸(数据集已经调整好了,不用修改)
上述是最基本的训练。参量全部使用默认的值,一些(部分)常见的可供修改的参量如下:
| 参数名 | 默认值 | 类型 | 说明 |
|---|---|---|---|
epochs |
100 | int | 训练的总轮次 |
batch |
16 | int | 每批次训练的样本数量 |
imgsz |
640 | int | 输入图像的尺寸(正方形边长) |
device |
‘cuda’ | str | 使用的设备(cuda、cpu) |
workers |
8 | int | 数据加载时的线程数 |
optimizer |
‘auto’ | str | 优化器类型(auto, SGD, Adam) |
lr0 |
0.01 | float | 初始学习率 |
lrf |
0.1 | float | 最终学习率与初始学习率的衰减比例 |
momentum |
0.937 | float | 优化器的动量系数 |
weight_decay |
0.0005 | float | 权重衰减系数,用于防止过拟合 |
warmup_epochs |
3.0 | float | 学习率预热的轮次数 |
warmup_momentum |
0.8 | float | 预热期间的动量值 |
warmup_bias_lr |
0.1 | float | 预热期间的偏置学习率 |
box |
7.5 | float | 边界框回归损失权重 |
cls |
0.5 | float | 分类损失权重 |
dfl |
1.5 | float | 分布式聚焦损失权重 |
hsv_h |
0.015 | float | 数据增强中的色调变化范围 |
hsv_s |
0.7 | float | 数据增强中的饱和度变化范围 |
hsv_v |
0.4 | float | 数据增强中的亮度变化范围 |
flipud |
0.0 | float | 垂直翻转概率 |
fliplr |
0.5 | float | 水平翻转概率 |
mosaic |
1.0 | float | 是否使用 Mosaic 数据增强 |
mixup |
0.0 | float | 是否使用 Mixup 数据增强 |
copy_paste |
0.0 | float | 使用 Copy-Paste 数据增强的概率 |
save_period |
-1 | int | 模型保存的间隔周期(-1 表示仅在最后保存) |
resume |
False | bool | 是否从上一次中断的训练继续训练 |
rect |
False | bool | 使用矩形训练(适合不同比例的图片) |
patience |
50 | int | 如果验证集的结果没有改善多少轮次后停止训练 |
verbose |
False | bool | 是否打印详细的训练信息 |
seed |
0 | int | 设置训练的随机种子 |
sync_bn |
False | bool | 是否在多 GPU 训练时使用同步批归一化 |
workers |
8 | int | 数据加载器的线程数 |
label_smoothing |
0.0 | float | 标签平滑的系数,通常用于减少过拟合 |
multi_scale |
False | bool | 是否使用多尺度训练 |
single_cls |
False | bool | 是否将所有类别视为一个类别进行训练 |
cache |
False | bool / str | 是否将数据集缓存到内存或磁盘中 (‘ram’, ‘disk’) |
pretrained |
True | bool | 是否使用预训练模型 |
cos_lr |
False | bool | 是否使用余弦退火学习率调度 |
save_json |
False | bool | 是否以 COCO 格式保存评估结果 |
save_hybrid |
False | bool | 是否在训练时保存混合精度模型 |
exist_ok |
False | bool | 是否允许覆盖已存在的训练输出文件夹 |
上表可能并不准确,详细请参见官方网页🔗官方提供的训练文档
以下是我的本次训练的全部参数(记录在输出文件夹的args文件中):
启动训练后:
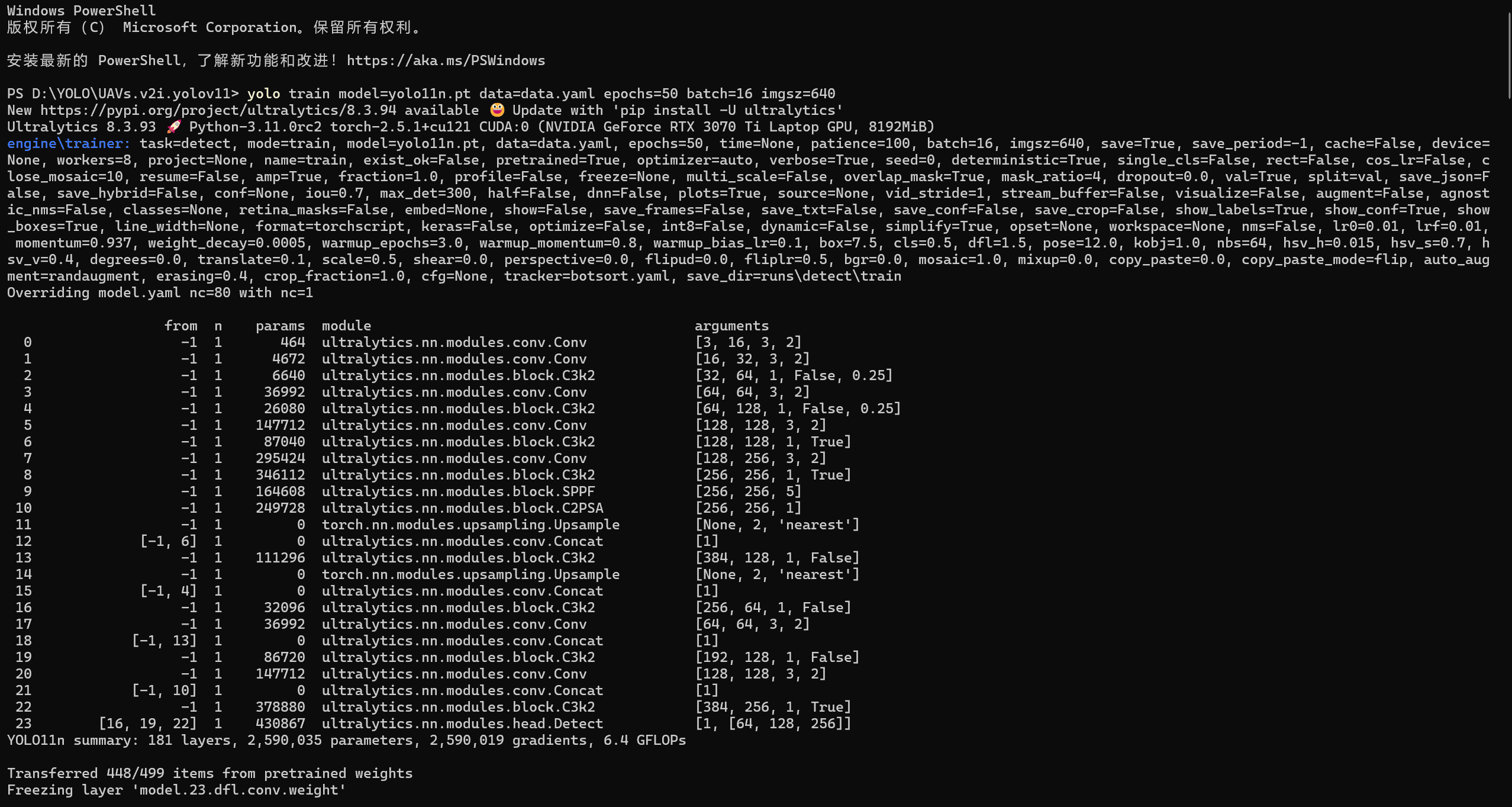
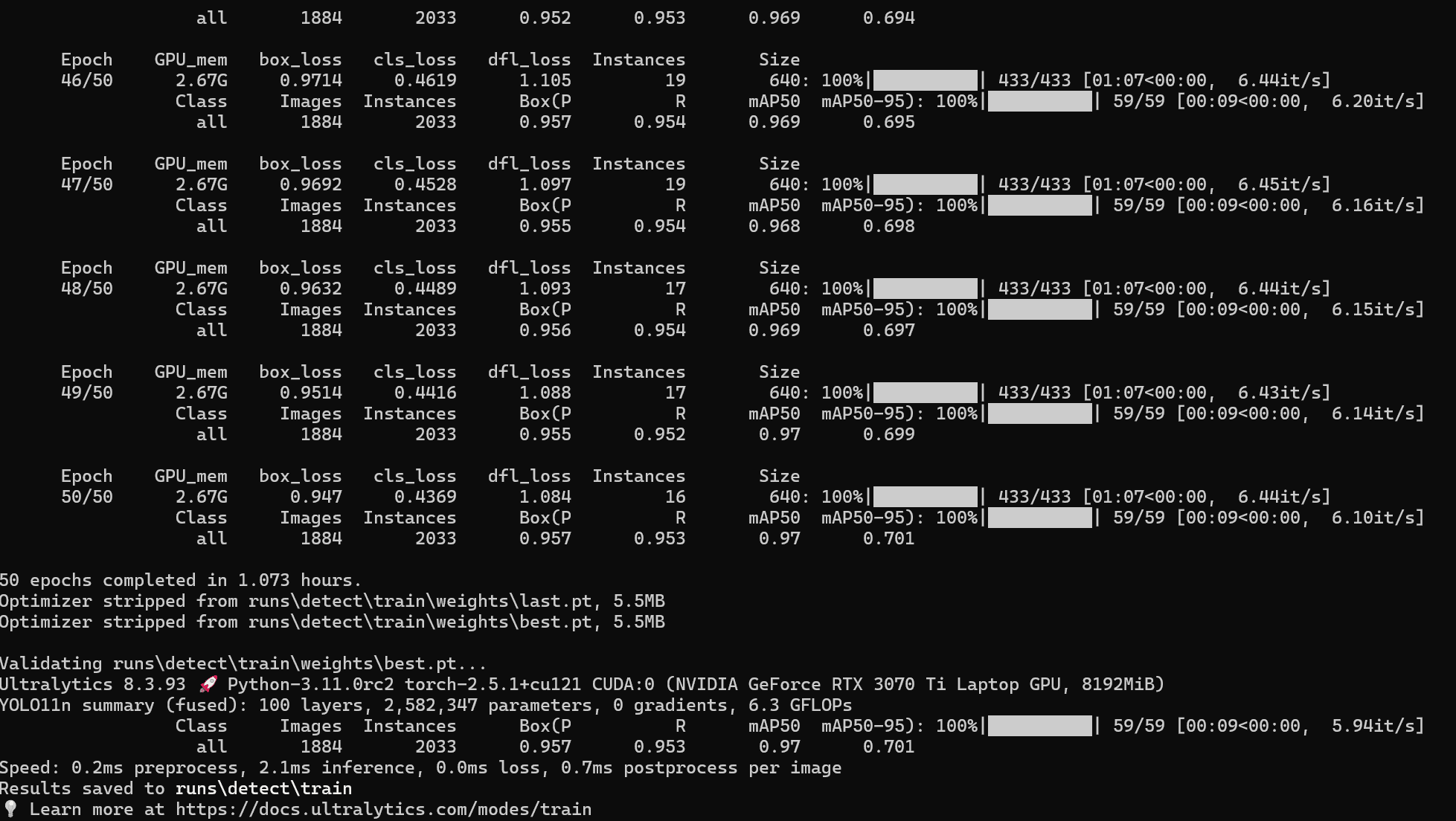
(除了将epochs调整为50外,其他均为默认,我的电脑是3070ti的显卡)经历了1个多小时后,完成了训练,可以看到多了下面这个文件夹/train:
在\runs\detect\train\weights下,有两个.pt文件,分别是last.pt和best.pt,last.pt是最后一次训练的模型,best.pt是最好的模型,一般来说,best.pt是最好的模型,可以用来进行推理。
模型推理
下面是一个简单的例子,用来实时检测无人机(其实跟开头用的是一个代码😁):
1 | import cv2 |
部分推理结果(默认输出,并不是上述代码的运行结果):
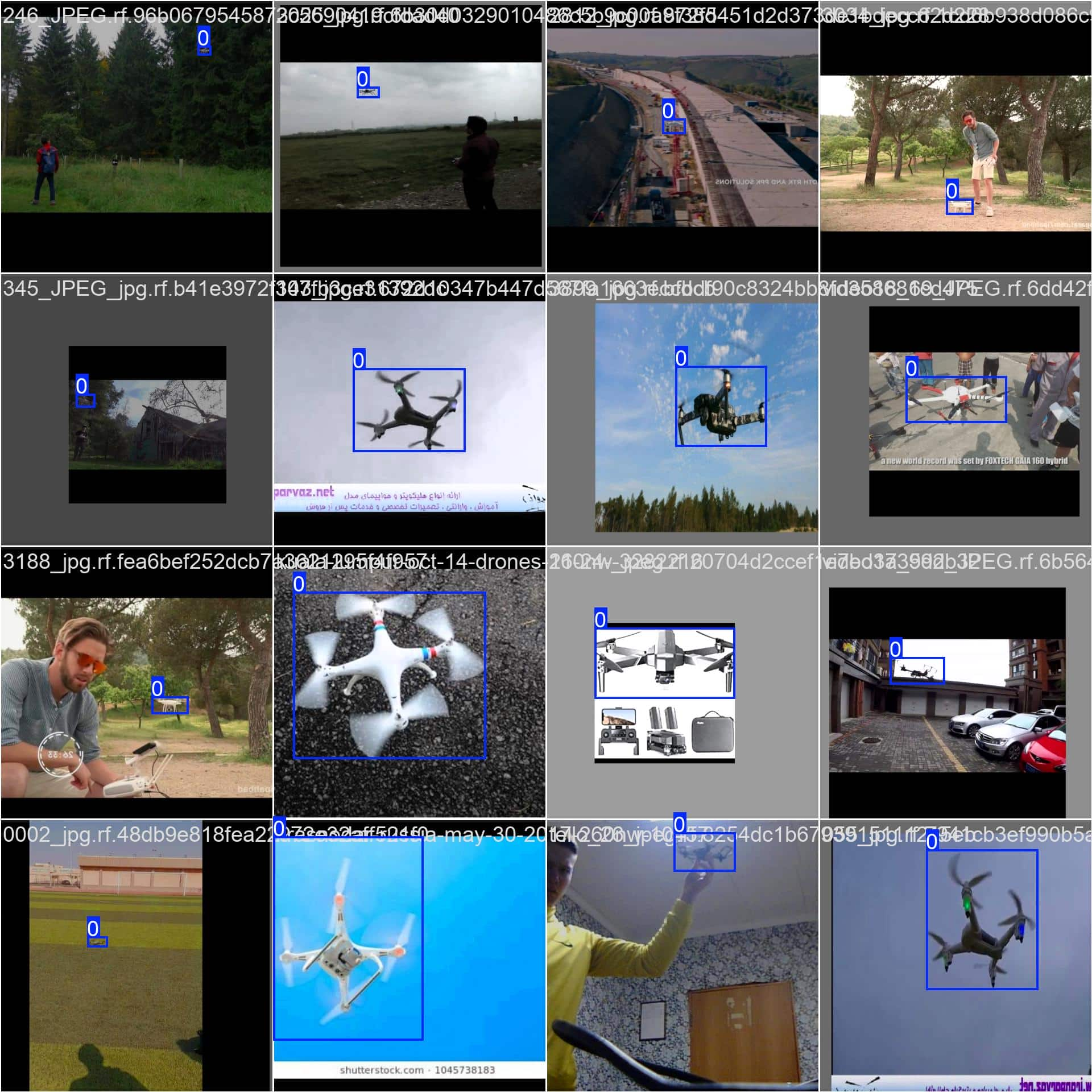
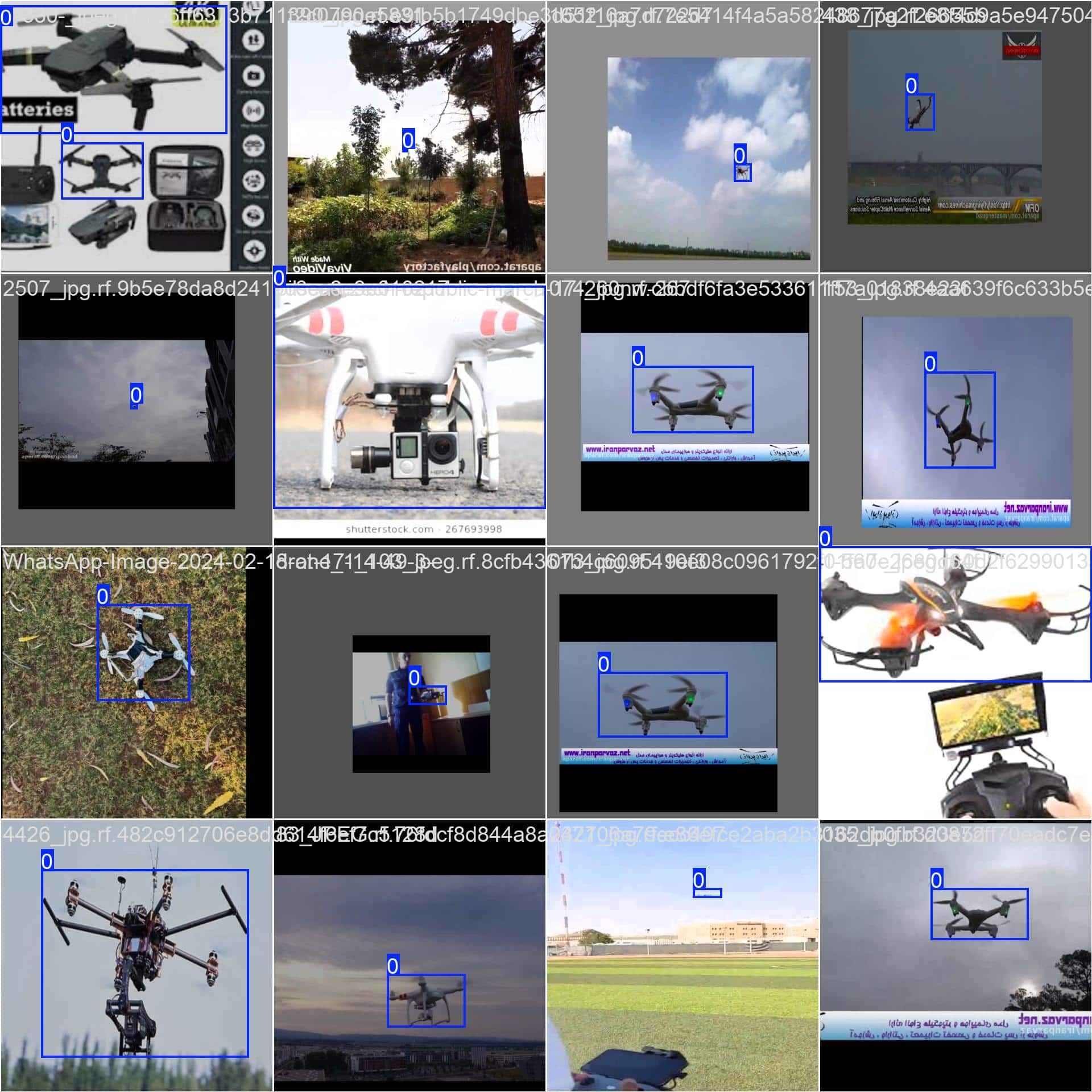


模型分析
在训练的输出文件夹里,有几张当前模型的大致情况,可以根据这些表格,来分析模型的训练详情。
混淆矩阵 (Confusion Matrix)
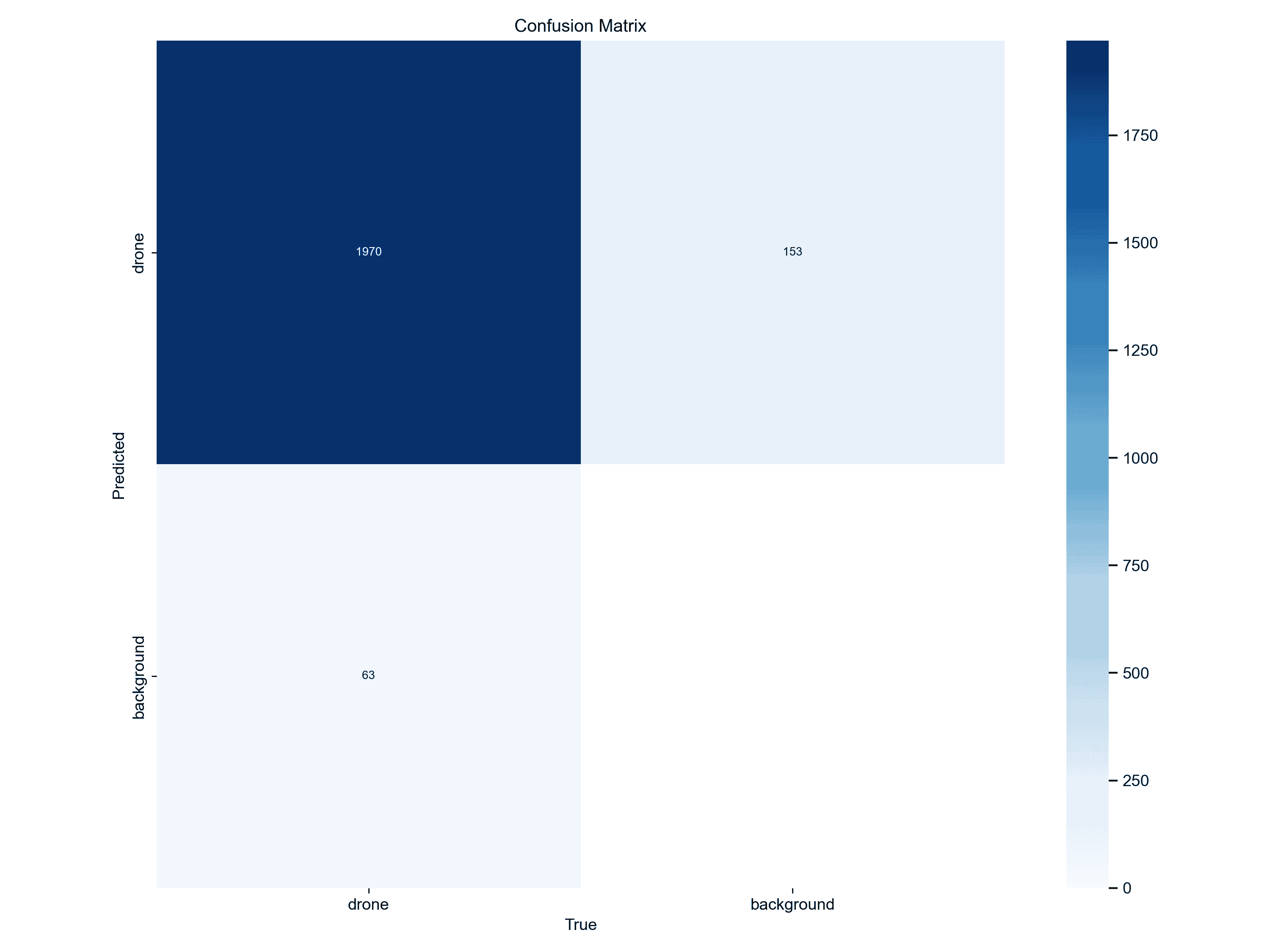
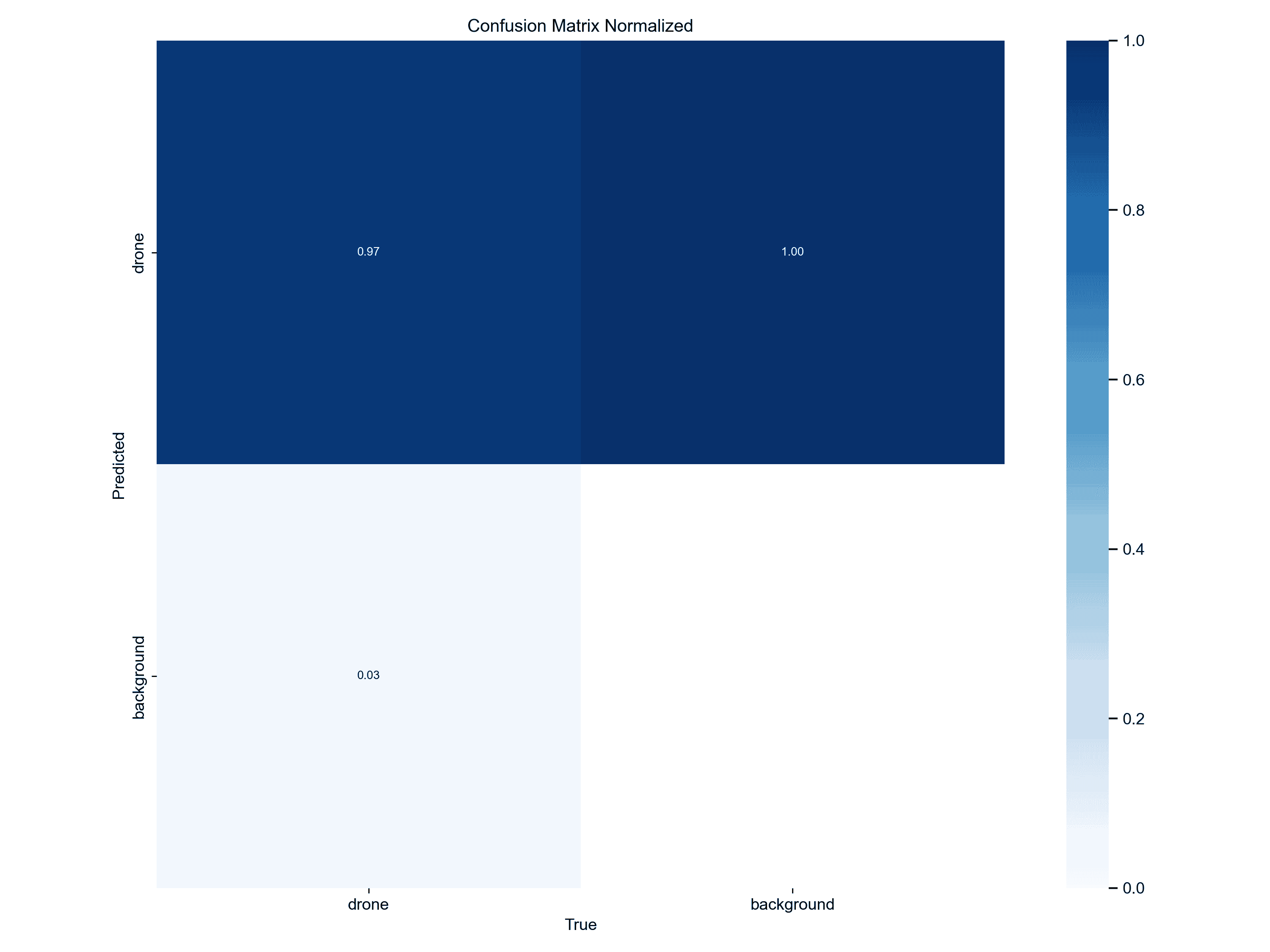
上两张图为归一化后的混淆矩阵,显示了模型在分类任务中的表现。横轴表示真实类别,纵轴表示模型的预测类别。图中有两个类别:drone 和 background。其中:
0.97:表示模型将真实的无人机正确识别为无人机的概率为 97%。
0.03:表示模型将无人机错误识别为背景的概率为 3%。
1.00:表示模型将背景正确识别为背景的概率为 100%。
粗略说明了模型对背景的识别非常准确,没有误判背景为无人机;在识别无人机时表现良好,尽管存在少量的误判。如果进一步优化模型,可以着重减少无人机的误判,通过调整置信度阈值或增加训练数据量。
F1-Confidence 曲线
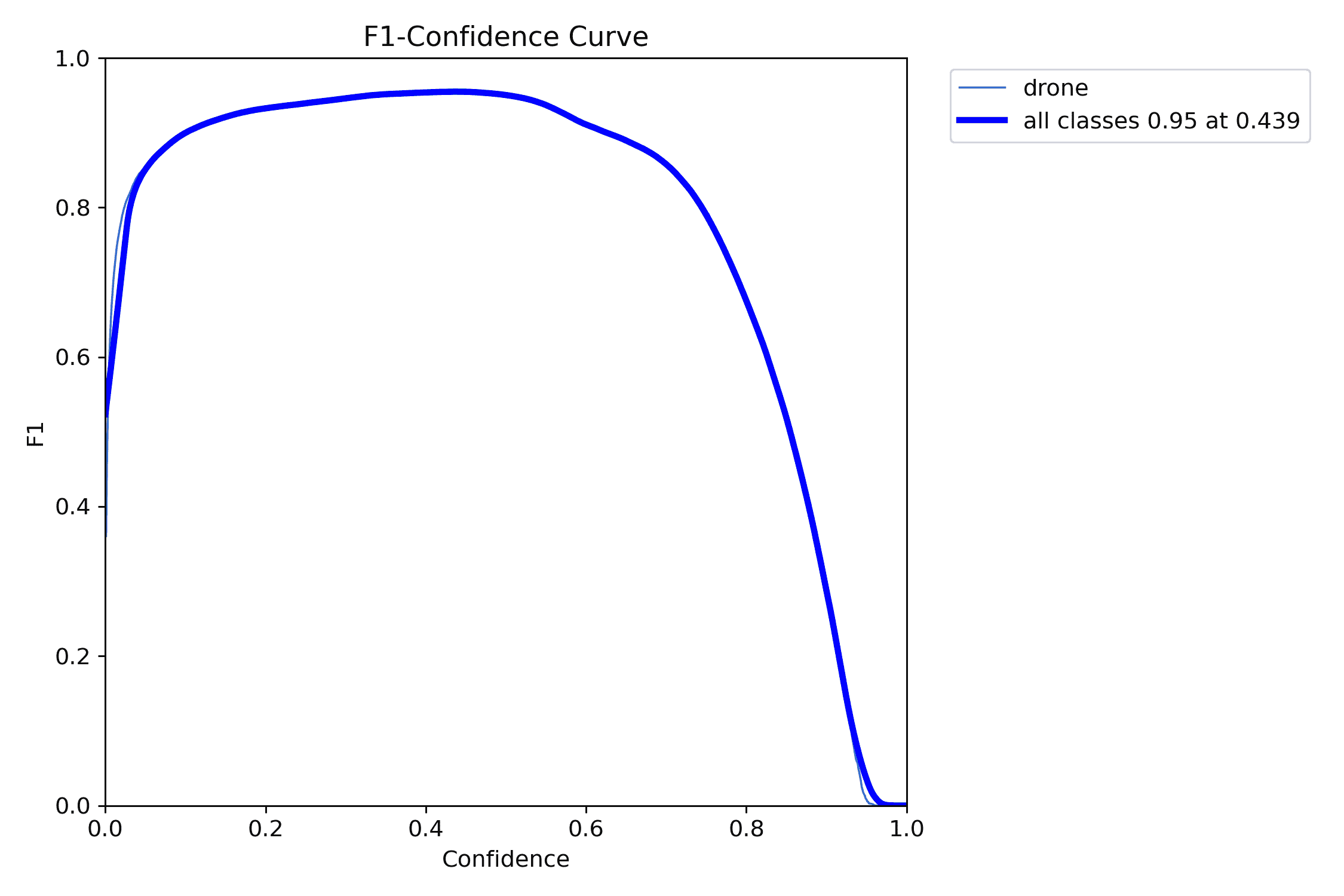
这是 F1 分数随置信度阈值变化的曲线。横轴表示模型的置信度阈值,纵轴表示 F1 分数。F1分数是精确率和召回率的调和平均值,用于衡量模型的综合性能。
从图中可以看到,最大 F1 分数为 0.95,在置信度阈值为 0.439 时达到最佳表现;在低置信度时,F1分数迅速上升,表明模型可以有效检测出大部分无人机;在较高的置信度时,F1分数下降,说明模型变得过于保守,可能漏检一些无人机,综合来看,模型的置信度阈值应该设置在 0.439 附近,以实现最佳的检测性能。
标签分布与边界框分布
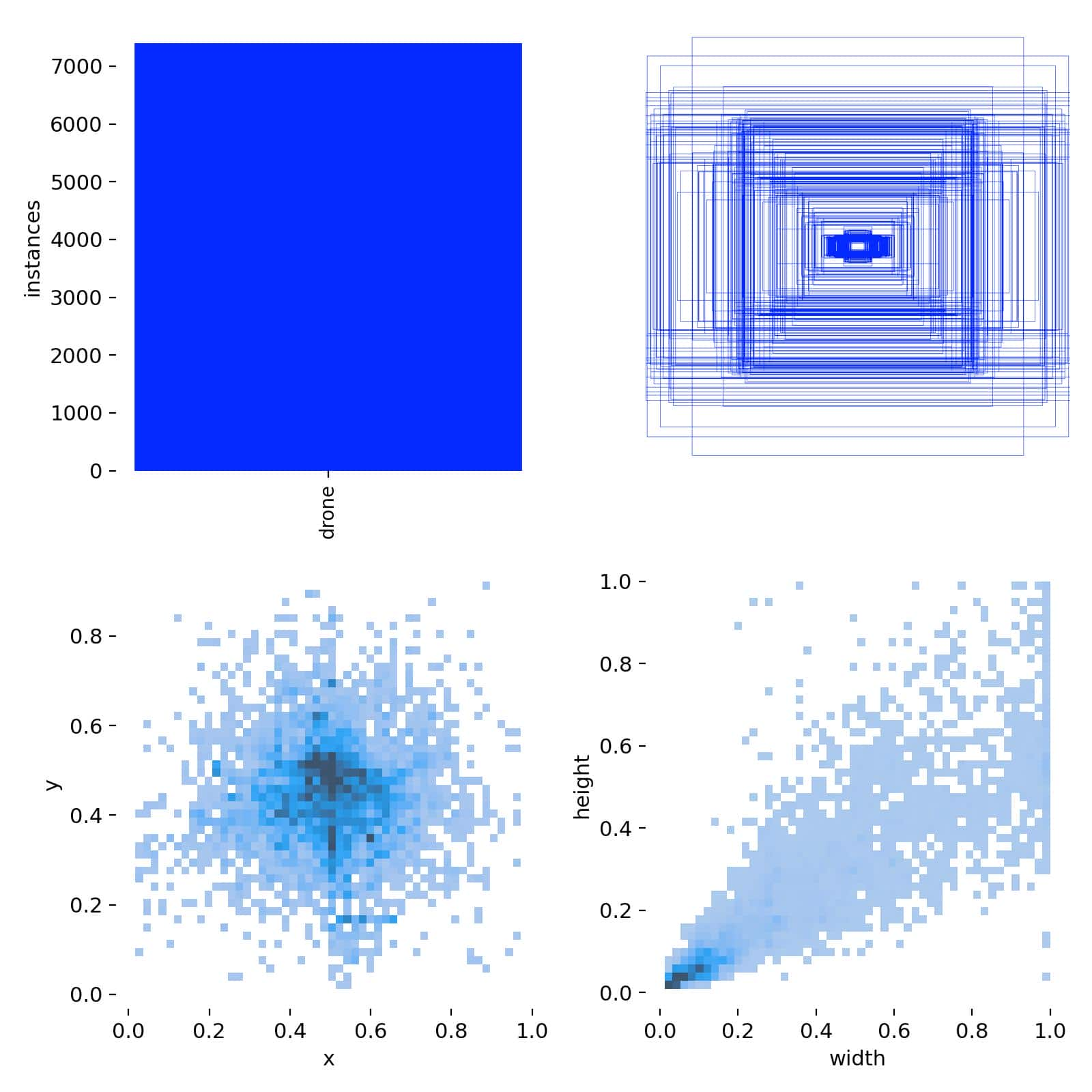
左上角:展示了数据集中标签的分布情况。这里显示出所有实例都属于 drone 类别。
右上角:边界框(Bounding Box)的分布图,显示标注框在图像中的位置和尺寸。中心位置的框较多,可能表明无人机通常位于画面中央。
左下角:边界框中心点的 (x, y) 分布直方图。黑色聚集的区域表明目标物体多集中在图像的中央。
右下角:边界框的 宽度 (width) 和 高度 (height) 分布。这里的聚集表示无人机的标注框尺寸有一定的规律,通常较小。
上图说明数据集存在明显的中心偏移,可能是由于无人机拍摄时常处于视野中央;标注框的尺寸也较为固定,表明数据集中无人机大小相对一致;数据分布良好,但需要确保数据集的多样性,避免模型产生位置和尺寸的偏差。
标签相关性矩阵
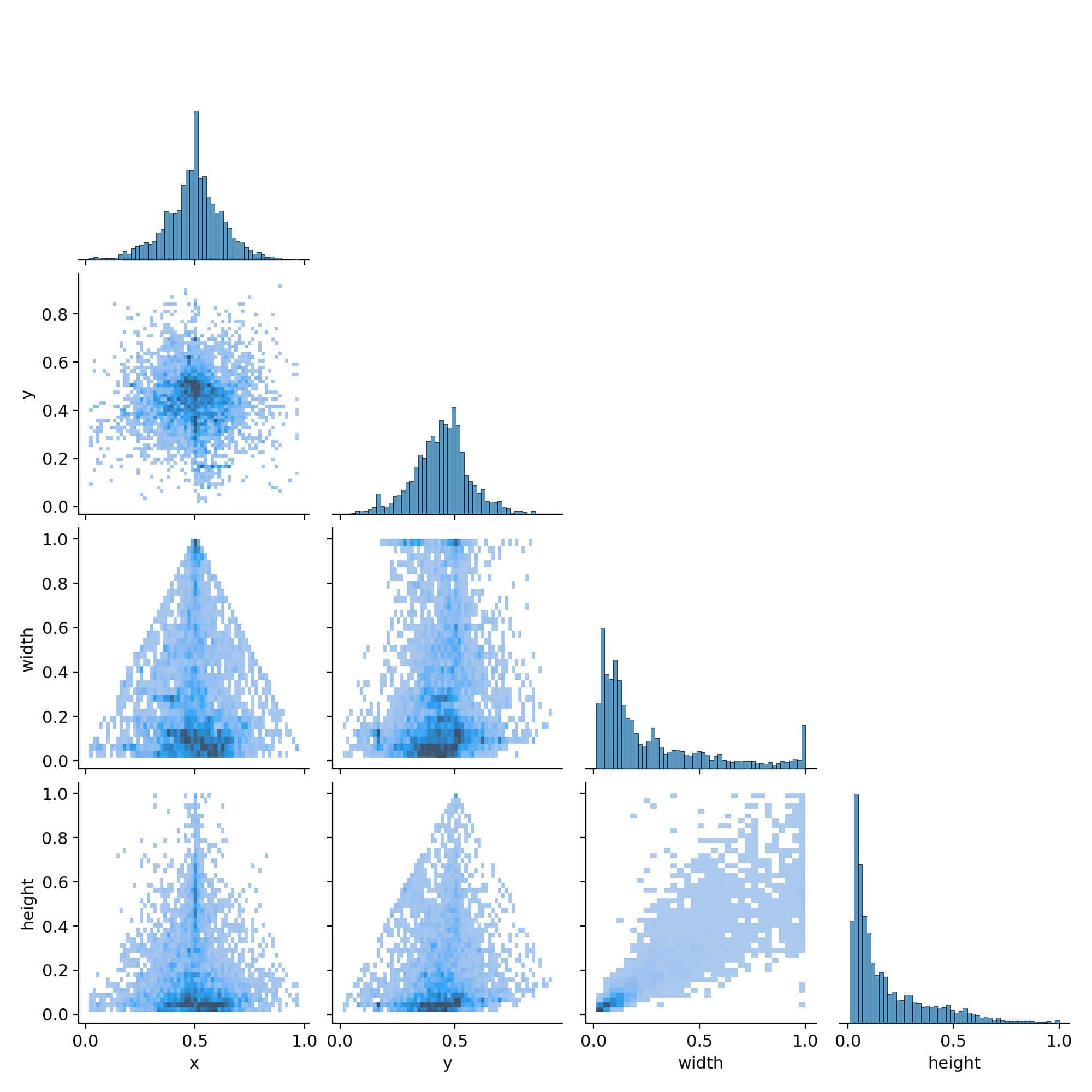
此图显示了边界框的特征相关性,包含位置 (x, y) 和尺寸 (width, height) 的相关性矩阵。
对角线分布:表示特征与自身的完美相关性,相关系数为 1。
上下三角部分:表示不同特征之间的相关性。
其中 x 和 y 的分布较均匀,表明数据在空间位置上分布合理。width 和 height 呈现一定的正相关性,意味着无人机的边界框通常是宽高成比例的。如果发现异常相关性,例如宽高之间过度相关,可能会导致模型对特定尺寸的目标物体产生偏见。
精确率-置信度曲线

横轴:模型的置信度阈值。
纵轴:精确率 (Precision),即检测到的目标中实际为正确检测的比例。
蓝色曲线:为不同置信度阈值下的精确率。
标注点:在置信度为 0.87 时达到最高精确率,接近 1.00。
从图中可以看出,模型的精确率表现非常好,特别在高置信度下仍保持较高的精确率;当前模型在置信度 0.87 附近可能是一个理想的平衡点。
精确率-召回率曲线(PR曲线)

它显示了在不同阈值下精确率和召回率之间的权衡。精确率表示模型预测为正例的样本中,有多少是真正的正例;召回率表示在所有实际为正例的样本中,有多少被模型正确预测。蓝色线表示 “无人机” 类别的精确率-召回率曲线,精确率为 0.970。较粗的蓝色线表示所有类别的精确率-召回率曲线,在 0.5 的阈值下,所有类别的 mAP(平均精确率)为 0.970。
该图表明模型在高精确率(接近 1)的情况下表现良好,并且在召回率接近 1 时,精确率急剧下降。这也说明模型在预测无人机时非常自信,并且在做出预测时选择性很强,仅识别它非常确定的实例。
召回率-置信度曲线
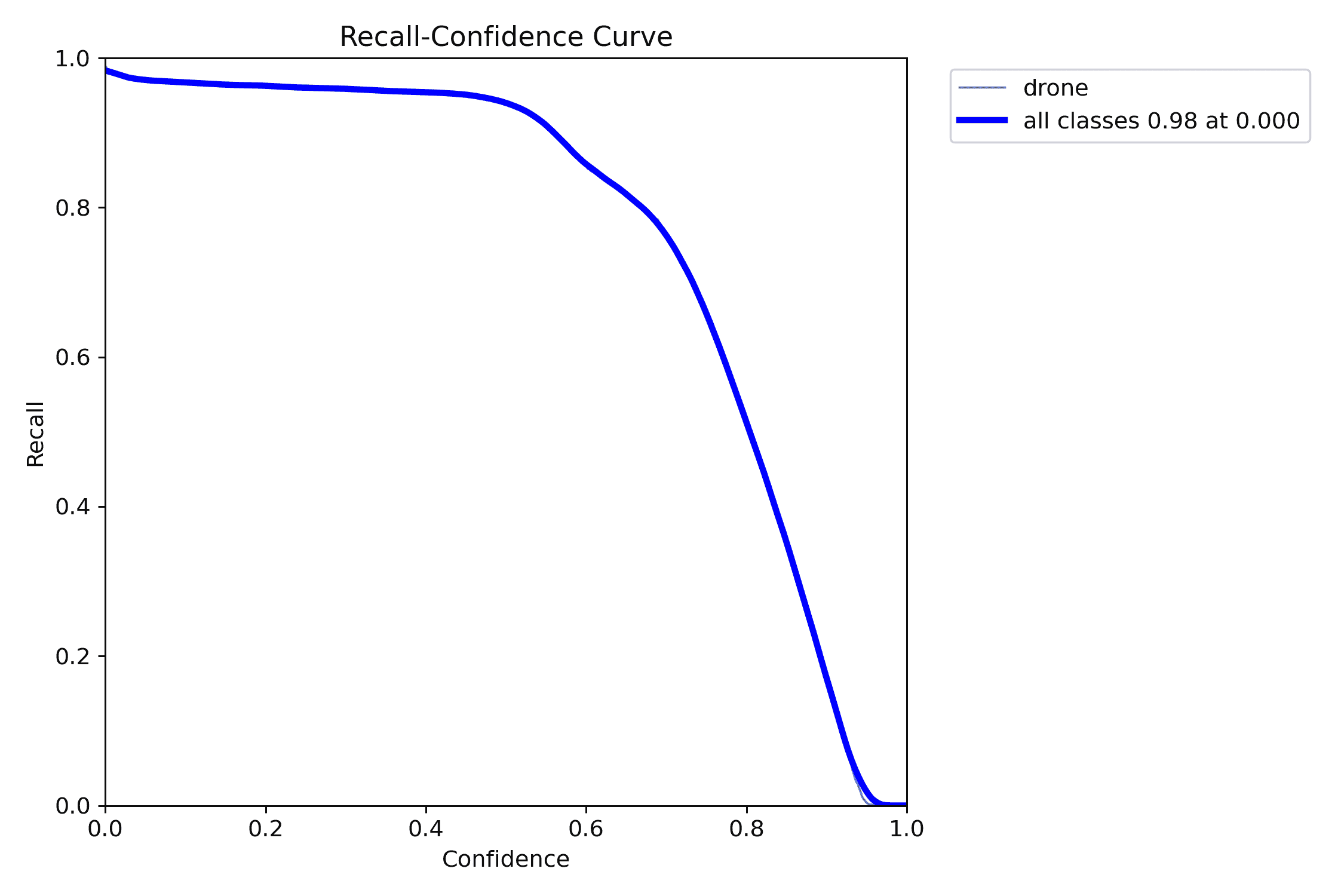
该曲线展示了随着置信度阈值变化,召回率的变化。置信度阈值指示模型在做出正向预测时需要的置信度水平。蓝色线代表无人机类别,当置信度非常低(0.000)时,召回率接近 0.98,但随着置信度的增加,召回率急剧下降。
模型最初识别几乎所有可能的实例(召回率高),但随着置信度阈值的升高,模型变得更加严格,因此召回率下降。这是典型的现象,即在置信度较高时,模型更具选择性,导致召回率下降。
损失和指标曲线
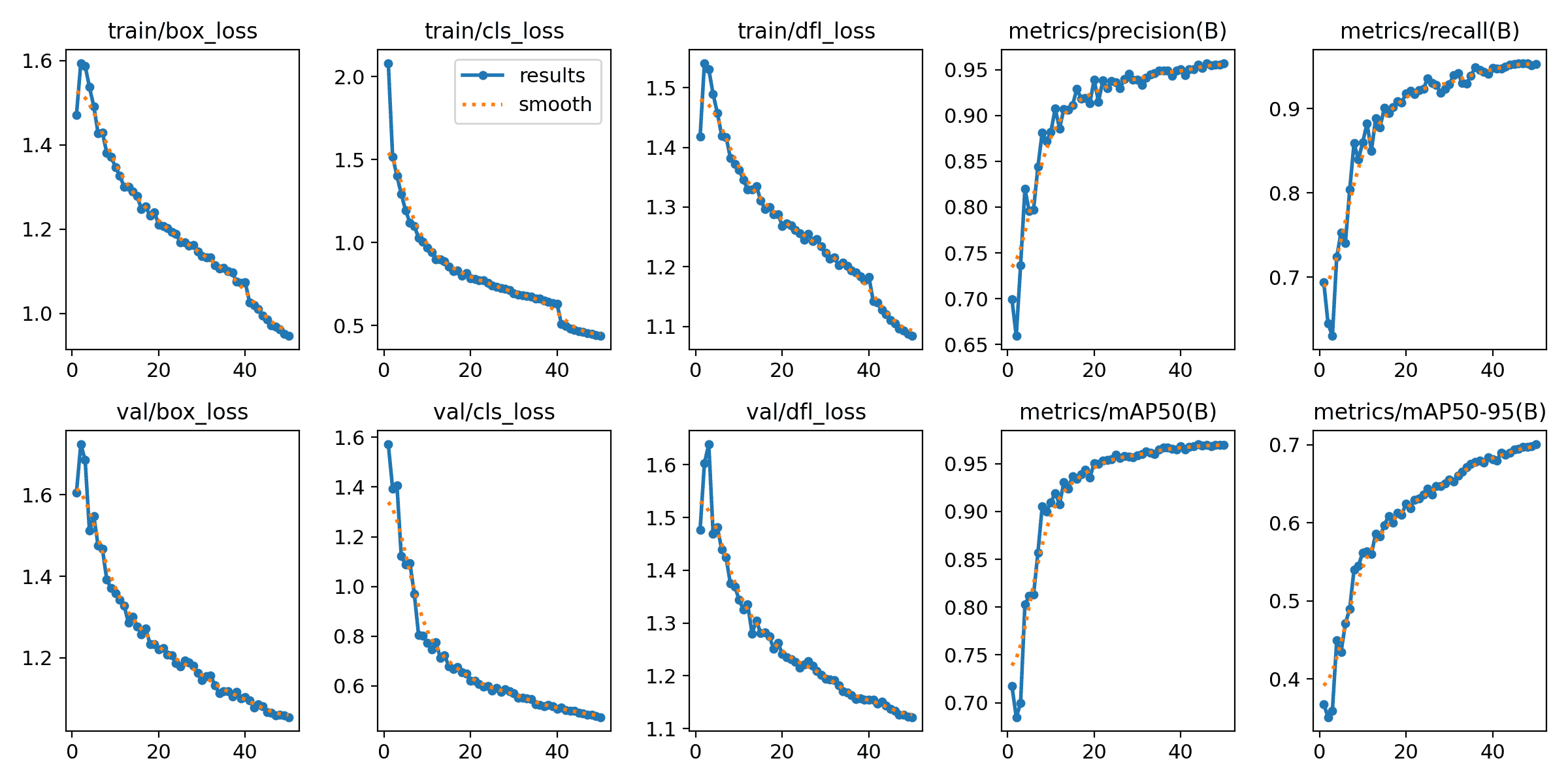
图中包含了与训练和验证相关的各种损失和指标曲线(随时间变化,单位为训练轮次):
训练损失:train/box_loss、train/cls_loss 和 train/dfl_loss 分别表示模型的框架损失、分类损失和分布特征损失。
验证损失:val/box_loss、val/cls_loss 和 val/dfl_loss 分别表示验证集上的相同损失指标。
指标:精确率、召回率、mAP@50 和 mAP50-95 分别是模型在不同阈值下的性能指标。
图中说明损失在训练过程中逐渐减少,表明模型随着每个训练轮次的进行在不断优化。蓝色线表示训练过程中的指标,橙色虚线 表示这些指标的平滑版本。精确率和召回率在训练和验证过程中都逐步提高,这表明模型在学习和泛化方面表现良好。验证损失和指标的趋势与训练数据类似,说明模型没有发生严重的过拟合,具有较好的泛化能力。
TO DO LIST
- 换一个更大的模型权重,YOLO11m 或者 YOLO11l
- 在更大的数据集上进行继续训练。其实我感觉9000多的数据集应该差不多了,后继继续在之前的基础上进行增量训练就行。
- 做一个闭环式的自训练模型,即:在日后的实际应用中,将检测到的无人机的图片(高于一定置信度的,比如 0.8 )自动加入到数据集中,并自动进行训练。使模型有一定的自学习能力,这样模型的准确率会越来越高。
- 完成该无人机检测系统的后端设计,与模型对接。
- 融合鸟类的检测模型,使其能够同时检测无人机和鸟类,以更精确区分无人机和鸟类,避免误判。
Comments